Factors Affecting Marketing Experimentation: Statistical significance in marketing, calculating sample size for marketing tests, and more
Here are answers to questions SuperFunnel Cohort members put in the chat of recent MEC200 and MEC300 LiveClasses for ChatGPT, CRO and AI: 40 Days to build a MECLABS SuperFunnel (feel free to register at that link to join us for an upcoming MECLABS LiveClass).
How many impressions or how much reach do we need for statistical significance?
I can’t give you a specific number, because the answer will vary based on several factors (described below). Also, MECLABS SuperFunnel Cohort members now have access to a Simplified Test Protocol in their Hub, and you can use that tool to calculate these numbers, as shown in Wednesday’s LiveClass.
But I included the question in this blog post because I thought it would be helpful to explain the factors that go into this calculation. And to be clear, I’m not the math guy here. So I won’t get into the formulas and calculations. However, a basic understanding of these factors has always helped me better understand marketing experimentation, and hopefully it will help you as well.
First of all, why do we even care about statistical significance in marketing experimentation? When we run a marketing test, essentially we are trying to measure a small group to learn lessons that would be applicable to all potential customers – take a lesson from this group, and apply it to everyone else.
Statistical significance helps us understand that our test results represent a real difference and aren’t just the result of random chance.
We want to feel like the change in results is because of our own hand. It’s human nature. A better headline on the treatment landing page, or a better offer. And we can see the results with our own eyes, so it is very hard to understand that a 10% conversion rate may not really be any different than an 8% conversion rate.
But it may just be randomness. “Why is the human need to be in control relevant to a discussion of random patterns? Because if events are random, we are not in control, and if we are in control of events, they are not random, there is therefore a fundamental clash between our need to feel we are in control and our ability to recognize randomness,” Dr. Leonard Mlodinow explains in The Drunkard’s Walk: How Randomness Rules Our Lives.
You can see the effect of randomness for yourself if you run a double control experiment – split traffic to two identical landing pages and even though they are exactly the same, they will likely get a different number of conversions.
We fight randomness with statistical significance. The key numbers we want to know to determine statistical significance are:
- Sample size – How many people see your message?
- Conversions – How many people act on your message?
- Number of treatments – For example, are you testing two different landing pages, or four?
- Level of confidence – Based on those numbers, how sure can you be that there really is a difference between your treatments?
And this is the reason I cannot give you a standard answer for the number of impressions you need to reach statistical significance – because of these multiple factors.
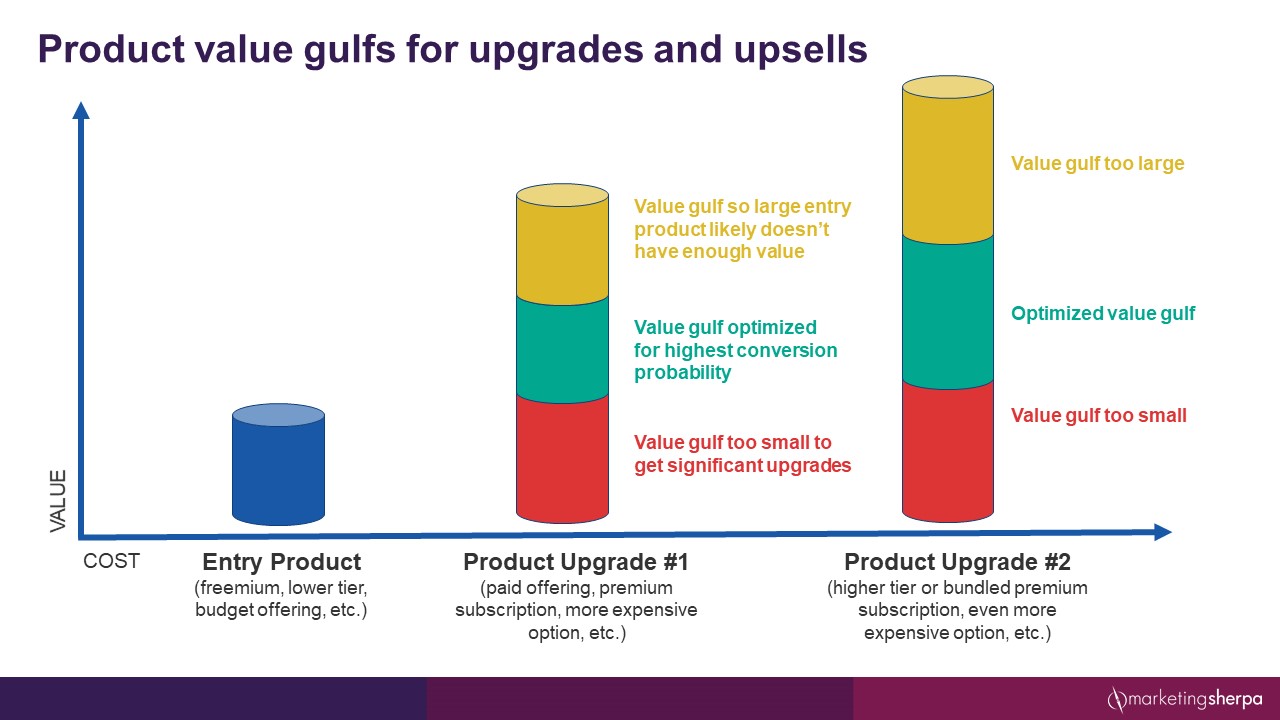
I’ll give you an (extreme) example. Let’s say your sample size is 100 and you have four treatments. That means, each landing page was visited by 25 people. Three of the landing pages each get three conversions, and the other landing page gets four conversions. Since so few people saw these pages and the difference in conversions is so small, how confident are you that they are different? Or perhaps you randomly had one more motivated person in that last group that gave you the extra conversion.
And this assumes an even traffic split, which you may not want to do based on how concerned you are about the change you are making. As we teach in How to Plan Landing Page Tests: 6 Steps to Guide Your Process, “Using an uneven traffic split is helpful when your team is testing major changes that could impact brand perception or another area of your business. Although the results will take longer to reach statistical significance, the test is less likely to have an immediate negative impact on business.”
Now, let’s take another extreme example. Say your sample size is 10,000,000 and you have just a control and a treatment. The control gets 11 conversions, but the treatment gets 842,957 conversions. In that case, you can be pretty confident that the control and treatment are different.
But there is another number at play here – Level of Confidence (LoC). When we say there is a statistically significant difference, it is at a specific Level of Confidence. How sure do you want to be that the control and treatment are different? For marketing experimentation, 95% is the gold standard. But 90%, or even 80% could be a enough if it is a change that likely isn’t going to be harmful, and doesn’t take too many resources to make. And the lower Level of Confidence you are OK with, the lower sample size you need and the less difference in conversions you need to be statistically significant at that LoC.
So is Estimated Minimum Relative Difference our desired/target lift if our test performs as expected?
Once you understand how statistical significance works (as I described in the previous question), the next natural question is – well, how does this affect my business decisions?
The first answer is, this understanding will help you run marketing experiments that are more likely to predict your potential customers’ real-world behavior.
But second answer is – this should impact how you plan and run tests.
This question refers to the Estimated Minimum Relative Difference in the Simplified Test Protocol that SuperFunnel Cohort members receive, specifically in the test planning section that helps you forecast how long to run a test to reach statistical significance. And yes, the Estimated Minimum Relative Difference is the difference in conversion rate you expect between the control and treatment.
As discussed above, the larger this number is, the less samples and time (to get those samples) it takes to run a test.
Which means that companies with a lot of traffic can run tests that reach statistical significance even if they make very small changes. For example, let’s say you’re running a test on the homepage of a major brand, like Google or YouTube, which get billions of visits per month. Even a very small change like button color may be able to reach statistical significance.
But if you have lower traffic and a smaller budget, you likely need to take a bigger swing with your test to find a big enough difference. This does not necessarily mean it has to require major dev work. For example, the headlines “Free courtside March Madness tickets, no credit card required” and “$12,000 upper level March Madness tickets, $400 application fee to see if you qualify” are very quick changes on a landing page. However, they are major changes in the mind of a potential customer and will likely receive very different results.
Which brings us to risk. When you run valid experiments, you decrease the risk in general. Instead of just making a change and hoping for the best, only part of your potential customer base sees the change. So if your change actually leads to a decrease, you learn before shifting your entire business. And you know what caused the decrease in results because you have isolated all the other variables.
But the results from your experiments will never guarantee a result. They will only tell you how likely there will be a difference when you roll out that change to all your customers for a longer period. So if you take that big swing you’ve always wanted to take, and the results aren’t what you expect, that may rein your team in from a major fail.
As we say in Quick Guide to Online Testing: 10 tactics to start or expand your testing process, “If a treatment has a significant increase over the control, it may be worth the risk for the possibility of high reward. However, if the relative difference between treatments is small and the LoC is low, you may decide you are not willing to take that risk.”
With a test running past 4 weeks, how concerned are you about audience contamination between the variants?
Up until now we’ve been talking about a validity threat called sampling distortion effect – failure to collect a sufficient sample size. As discussed, this could mean your marketing experiment results are due to random variability, and not a true difference between how your customers will react to your treatments when rolled out to your entire customer set.
But there are other validity threats as well. A validity threat simply means that a factor other than the change you made – say, different headlines or different CTAs – was the reason for the difference in performance you saw. You are necessarily testing with a small slice of your total addressable market, and you want to ensure that the results have a high probability of replicability – you will see an improvement when you roll out this change to all of your potential customers.
Other validity threats include instrumentation effect – your measurement instrument affecting the results, and selection effect – the mix of customers seeing the treatments do not represent the customers that you will ultimately try to sell to, or in this case, the same customer seeing multiple treatments.
These are the types of validity threats this questioner is referring to. However, I think there is a fairly low (but not zero) chance of these validity threats only coming from running the test (not too much) past four weeks. While we have seen this problem many years ago, most major platforms have gotten pretty good at assigning a visitor to a specific treatment and keeping them there on repeat visits.
That said, people can visit on multiple devices, so the split certainly isn’t perfect. And if your offer is something that calls for many repeat visits, especially from multiple devices (like at home and at work), this may become a bigger validity threat. If this is a concern, I suggest you ask your testing software provider how they mitigate against these validity threats.
However, when I see your question, the validity threat I would worry about most is history effect, an extraneous variable that occurs with the passage of time. And this one is all on you, friend, there is not much your testing software can do to mitigate against it.
As I said, you are trying to isolate your test so the only variables that affect the outcome are the ones you’ve purposefully changed and are intending to test based on your hypothesis. The longer a test runs, the harder this gets. For example, you (or someone else in your organization) may choose to run a promotion during that period. Maybe you can keep a tight lid on promotions for a seven-day test, but can you keep the promotion wolves at bay in your organization for a full two months?
Or you may work at an ecommerce company looking to get some customer wisdom to impact your holiday sales. If you have to test for two months before rolling anything out, you may test in September and October. However, customers may behave very differently earlier in the year than they would in December, when their motivation to purchase a gift near a looming deadline is a much bigger factor.
While a long test makes a history effect more likely, it can occur even during a shorter test. In fact, our most well-known history effect case study occurred during a seven-day experiment because of the NBC television program Dateline. You can read about it (along with info about other validity threats) in the classic MarketingExperiments article Optimization Testing Tested: Validity Threats Beyond Sample Size.
Join us for a Wednesday LiveClass
As I mentioned, these questions came from the chat of recent LiveClasses. You can RSVP now to join us for an upcoming LiveClass. Here are some short videos to give you an idea of what you can learn from a LiveClass…
“If there’s not a strong enough difference in these two Google ads…the difference isn’t going to be stark enough to probably produce a meaningful set of statistics [for a marketing test]…” – Flint McGlaughlin in this 27-second video.
“…but that’s what Daniel was really touching on a moment ago. OK, you’ve got a [marketing] test, you’ve got a hypothesis, but is this really where you want to invest your money? Is this really going to get the most dollars or the most impact for the energy you invest?…” – Flint McGlaughlin, from this 46-second video about finding the most important hypotheses to test.
How far do you have to go to with your marketing to take potential customers from the problem they think they have, to the problem they do have? I discuss this topic while coaching the co-founders of an eyebrow beauty salon training company on their marketing test hypothesis in this 54-second video.